Fincons Fast Data Lake bietet eine neue Lösung für die Entwicklung digitaler Anwendungen, die all diesen Anforderungen gerecht wird und in alle bekannten Front-End-Technologien wie Web-Single-Page-, HTML5-, CSS-, Angular-, React- und Progressive-Web-Apps integriert ist. Fincons hat diese innovative und bahnbrechende Lösung für Big Data entwickelt und dabei auf seine Erfahrungen beim Scouten von Marktkomponenten sowie beim Testen im Hands-On Lab zurückgegriffen.
Fincons Fast Data Lake ermöglicht die Entwicklung von APIs, die Daten aus einem Hochleistungsdatenspeicher lesen, die mithilfe eines einzigen hochentwickelten Verfahrens von Legacy-Systemen nahezu in Echtzeit eingespeist werden, wodurch eine sehr schnelle Markteinführungszeit mit geringen Wartungskosten kombiniert wird.
.
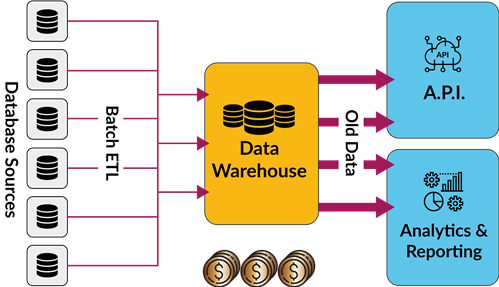
Traditionelle Vorgehensweise
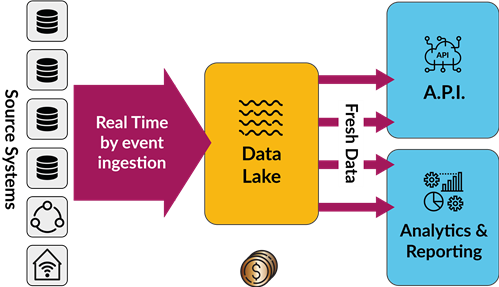
Mit Fincons Fast Data Lake
Einzelheiten
- Anpassunggähigkeit
Datenaufnahme aus verschiedenen Quellen, anpassbar an jedes Volumen, jede Geschwindigkeit und jeden Datentyp. - Flexibilität
Es können einzelne Architekturkomponenten ausgewählt werden, um die Lösung an bestimmte Anforderungen und Umgebungen anzupassen. Die Erstkonfiguration kann jederzeit geändert werden. - Integration
Standard-APIs für die perfekte Integration über alle Touchpoints hinweg. Bereits vorhandene Berichts- und Analysetools müssen nicht ersetzt werden. - Cloud-Bereit
Die Lösung kann vor Ort in proprietären oder Cloud-Umgebungen implementiert werden. - Echtzeit
Dank einer einzigen hochentwickelten Prozedur werden Daten innerhalb weniger Millisekunden von der Quelle zum Ziel verschoben. - Geringe Einricht- und Betriebskosten
Schnelle Konfiguration; Die Wartungs- und Entwicklungskosten sind geringer als bei herkömmlichen Plattformen; ETL-basierte Systeme. - Geringe Auswirkung
Keine Auswirkung auf die Leistung der Gesamtstruktur der Quelldaten.
Benefits
- Optimierte API-Leistung
Weil Daten beim Laden in kohärenter Weise denormalisiert werden, wirkt sich das Rechenlast nicht auf Suchvorgänge aus. - Peak Request Management
Bei Anforderungsspitzen wird die Auslastung vom Data Lake verwaltet, ohne dass dies Auswirkungen auf die Back-End-Vorgänge hat. - Entladen des Hauptrahmens
Die Maschinenleistung für Anforderungen wird vom Back-End-System auf den Data Lake verlagert, wodurch die Belastung für ältere Systeme verringert wird. - Optimierung der TCO
Keine ETL-Entwicklungs- oder Wartungskosten: Niedrige Einführungskosten basieren auf der tatsächlichen Nutzung. - Immer aktiv
Die Lösung ist rund um die Uhr aktiv und überwindet so die durch die Back-End-Verfügbarkeit verursachten Einschränkungen. - Google-like-Suche
Diese intuitive Funktion, mit der Benutzer vertraut und bevorzugt wird, kann problemlos zu Frontends hinzugefügt werden.